Eating off the floor
There is often a debate about how agile delivery fits with other approaches and a conference I went to earlier in the year was no exception. In this conference, CMMI Made Practical, people were asking should we “do CMMI” or “do Agile”. This question mirrors the one I often hear about: “Should we do PRINCE2 or Agile”? It’s a question that actually misleads people. At the panel session for the conference wrap up, one panelist (me!) said that comparing CMMI and Agile or comparing PRINCE2 and Agile is a nonsense; it’s like comparing tables and chairs – they are different; but you can use them together, unless you want to eat off the floor”.
The distinction is very clear:
- “Agile delivery” is done at work package level, with each sprint a representing a work package;
- Each “Release” can be represented as a project stage;
- Classic project management is the governance wrapper.
- The early project stages are about business need, strategic fit and architecture.
- The later project stages are about validation and deployment.
- The agile bit is in the middle.
- A project may comprise both agile and classic work packages.
- Some good agile practices and are good project practices.
Taking classic and agile to an extreme
At that conference, I learnt about an organisation which had taken the above concepts to an extreme. I first came across it last November, but only realised who the company was at last week’s conference, when they presented their case study – SITA.
This is not just about software development but truly complex, platform based systems engineering. In other words it is something and large technologu based company might take note of and do some “health checks” on.
Here are some sizing metrics:
- Distributed workforce in London, India, USA in 18 locations
- Five primary system domains
- 52,482 function points
- Peak staffing: 703
- Peak scrum teams: 61
So, it’s complex, distributed and off-shored. And in case you doubt it, this system does everything for 90% of airlines around the world before you get to the airport, at the airport, in the air and getting out of the airport, serving both the consumer directly as well as the airlines.
What is their key?
At the core of what they have done is created a classic project management wrap around agile delivery. They told me afterwards, that if anyone thinks they can do “agile” on this scale without without project management, they just prove they haven’t a clue. So what have they done?
At the heart is the Scrum, with its daily inspections, 2 weekly sprints and teams of about 8 people. A classic project stage is made up of 6 sprints (3 month long stages). They have the normal, input of prioritised requirements and an output of working software, giving them an increment in functionality. Within a sprint they do all the expected continuous integration and unit testing. In other words, good scrum stuff.
However because of the size and complexity of the system this is not enough. They have 5 streams of sprints going on at any time, with start and end points synchronized. They need to be able to draw these together and so before any agile development happens, they need to work through the requirements and prepare or update the architecture. Having a strongly managed architecture is key. Interfaces matter.
After the agile teams have delivered “working software”, there are four more project stages:
- Non-functional tests, integration and performance tests
- User acceptance test
- Operational acceptance tests leading to delivery into production.
That is to say, it is a 7 stage project, with the third stage being agile (and sometimes the second also being agile).
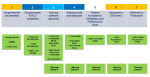
The seven project stages.
Source Presentation, CMMI Made Practical 2012, Lamri
To make sure that the software coming out of the teams works, each team has a sandbox environment, which replicates the full build at that point in time to check actual interfaces. This means there are fewer defects needing to be trapped in the later formal verification stages. They say this is expensive on environments, but what is the point of writing something that either fails or simply won’t sit on the final hardware with everything else. As you can imagine, change control and configuration management are vital.
They have a core architecture team who continuously tune the architecture as more information emerges. Architecture is designed to minimise system interfaces. Often requirements for particular sprints are driven by this team in order to ensure interfaces are built in a co-ordinated way across sprints and that sets of software can be deployed in a useful way. Working software, in isolation, is useless software, unless it fits into a wider, usable application or system. Inevitably there is rework resulting from changing architecture, so their sprints have time slots for making sure this happens. They are also clear with their suppliers that rework resulting from architecture changes are different to those resulting from poor workman ship. They expect 20 to 30 % rework but as a result of managing this, defects are trapped far earlier and overall delivery speeds up. They never leave rework for “sprint 6”, their last sprint. The approach of leaving all this until later in their view is counter productive.
Is it a success?
They say it is. By using their approach:
- Their delivery schedule has reduced by 50%
- Cost per function point down 43%
- Defect density reduced by 40%
Sounds good to me; what do you think? Have you any stories to support or challenge this?

 The Programme and Portfolio Workout has been launched. Together with its companion, The Project Workout, this book aims to help you run your organization in a structured, yet agile way so
The Programme and Portfolio Workout has been launched. Together with its companion, The Project Workout, this book aims to help you run your organization in a structured, yet agile way so 



